Ein Roboter lernt, Atmung zu verstehen – Teil 1

Praxis-Beispiel zu neuronalen Netzen
Ein Frühgeborenes liegt schlafend auf der Intensivstation, um es herum Schläuche, leise piepsende Geräte und – ein Roboter. Der Roboter schaut das Baby ruhig und aufmerksam an, überwacht unermüdlich seine Atmung. Er lernt, wie die kurzen Atmungszyklen verlaufen, ob sie schneller oder langsamer werden und wie stark der kleine Brustkorb sich dabei hebt und senkt. Bei jeder Einatmung aktiviert der Roboter im Bruchteil einer Sekunde die Vernebelung eines Medikaments, das in der Lunge des Kindes gegen eine Infektion wirkt. Natürlich ist nicht er allein zuständig für das Wohl des Neugeborenen. Eine Kinderärztin hat ihm zu Beginn gezeigt, was genau er machen soll und nun macht er das – auf ihre Anweisung hin – seit Stunden, ohne ein einziges Mal wegzusehen.
Klingt das wie Science-Fiction? Wenn wir uns den Roboter als piepsendes Gerät vorstellen, ausgestattet mit einem Sensordeckchen statt Augen, um die Atmung des Kindes zu beobachten, dann ist dieses Szenario nicht so weit von der Realität entfernt. Überwachungsgeräte gehören in der Medizin bekanntlich längst zum Alltag. Sie beobachten Herzrate, Blutzucker, die Sauerstoffversorgung im Blut und weitere Körperfunktionen. Die Vorteile: Unter anderem bleiben sie auch bei den monotonsten Aufgaben immer gleich aufmerksam und können auch über lange Zeiträume kosteneffizient für jeden Patienten und jede Patientin eingesetzt werden.
Aber wie sieht es mit dem Lernen aus? Wie realistisch ist es, dass der Roboter sich nur ansehen musste, was er tun soll und das dann nachahmen kann? Auf diesem Blog gibt es bereits einen Artikel, der beleuchtet, was es mit den „Buzzwords“ zum Thema Künstliche Intelligenz und Maschinelles Lernen eigentlich auf sich hat [1]. Selbstlernende Algorithmen und Geräte werden bereits in vielen Bereichen eingesetzt. Neben autonom fahrenden Autos, der Spracherkennung auf dem Smartphone und der Auswertung von Börsenzahlen finden sie auch in der medizinischen Branche langsam Einzug. Der weitere Vorteil, der sich daraus ergibt: Die Maschinen passen sich auf den individuellen Patienten oder die Patientin an. Sie können abhängig von deren Eigenschaften Entscheidungsgrundlagen für die Diagnose durch Ärztinnen und Ärzte liefern und, wenn sie für Überwachungsaufgaben eingesetzt werden, ihre Beobachtungen optimieren.
Aber können wir maschinelles Lernen für den beschriebenen Fall überhaupt einsetzen? Und wie können wir uns dieses „Lernen“ vorstellen? Welche Technologien benötigen wir? Wie können wir den Lernprozess optimieren? Und kann ein neuronales Netz unsere Daten am Ende besser auswerten als klassische Signalverarbeitungsverfahren? Diese Fragen haben sich uns gestellt, als wir überlegt haben, wie wir die Datenauswertung im Forschungsprojekt FlexMax (Flexible aktive Sensormatrix für medizinische Anwendungen) vornehmen wollen. Das neuronale Netz ist dabei eine von mehreren Optionen, mit denen wir die aufgezeichneten Sensordaten innerhalb der Forschungsumgebung auswerten.
Einen kleinen Einblick in unsere Vorgehensweise und unsere Ergebnisse möchten wir hier geben. Der Blogartikel unterteilt sich in zwei Teile, von denen der erste ein einführendes Beispiel gibt und einige theoretische Grundlagen erläutert. Der zweite Teil beschreibt dann unsere Vorgehensweise und die Erfahrungen, die wir sammeln konnten.
Einführendes Beispiel
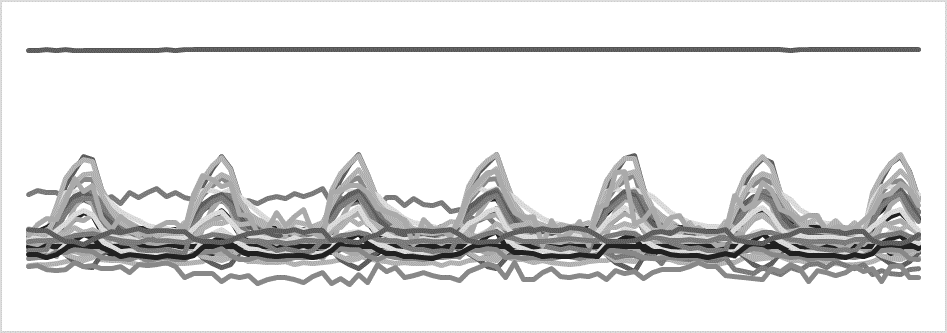
Sehen wir uns dieses Bild an. Kannst Du in diesem Signal die Einatmungsperioden identifizieren? Alles, was wir dazu wissen: Hier sind Sensordaten mehrerer Sensoren über die Zeit eingetragen. Erstmal sieht das ziemlich wirr aus. Wahrscheinlich kannst Du erraten, dass es eine Rolle spielt, ob die einzelnen Datenkurven sinken oder steigen. Vielleicht kannst Du auch identifizieren, dass der oberste, gerade Datensatz kaum Information beiträgt. Wenn es Dir aber geht wie mir, kannst Du nicht mit Sicherheit sagen, in welchen Zeiträumen das Signal eine Einatmung darstellt.
Wenn uns jetzt jemand eine konkrete Handlungsanweisung dazu geben würde (z.B.: „berechne den Mittelwert aller Kurven und identifiziere dann jeweils den niedrigsten und höchsten Punkt“), dann wäre das kein Problem. In etwa so können wir uns die Vorgehensweise mit klassischen Signalverarbeitungsverfahren vorstellen.
Schauen wir uns jetzt das nächste Bild an. Hier ist für die ersten Zeitschritte markiert, wann eine Einatmung stattfindet. Unser Gehirn versteht diese Information blitzschnell und kann sie direkt auf das weitere Signal übertragen. Du bist jetzt vermutlich in der Lage, mit relativ hoher Präzision die Einatmungsperioden für das gesamte restliche Signal einzuzeichnen. Dazu müssen wir nicht beantworten können, welche der Kurven besonders relevant sind. Wir brauchen auch nicht explizit zu ermitteln, wo die Extremwerte liegen oder wie stark die Steigung ist. Unser Gehirn überträgt die Information einfach so. Und genau dieses intuitive, reproduzierende Denken ist das, was durch neuronale Netze nachgeahmt werden soll. Wie das funktionieren kann, soll dieser Artikel zeigen.
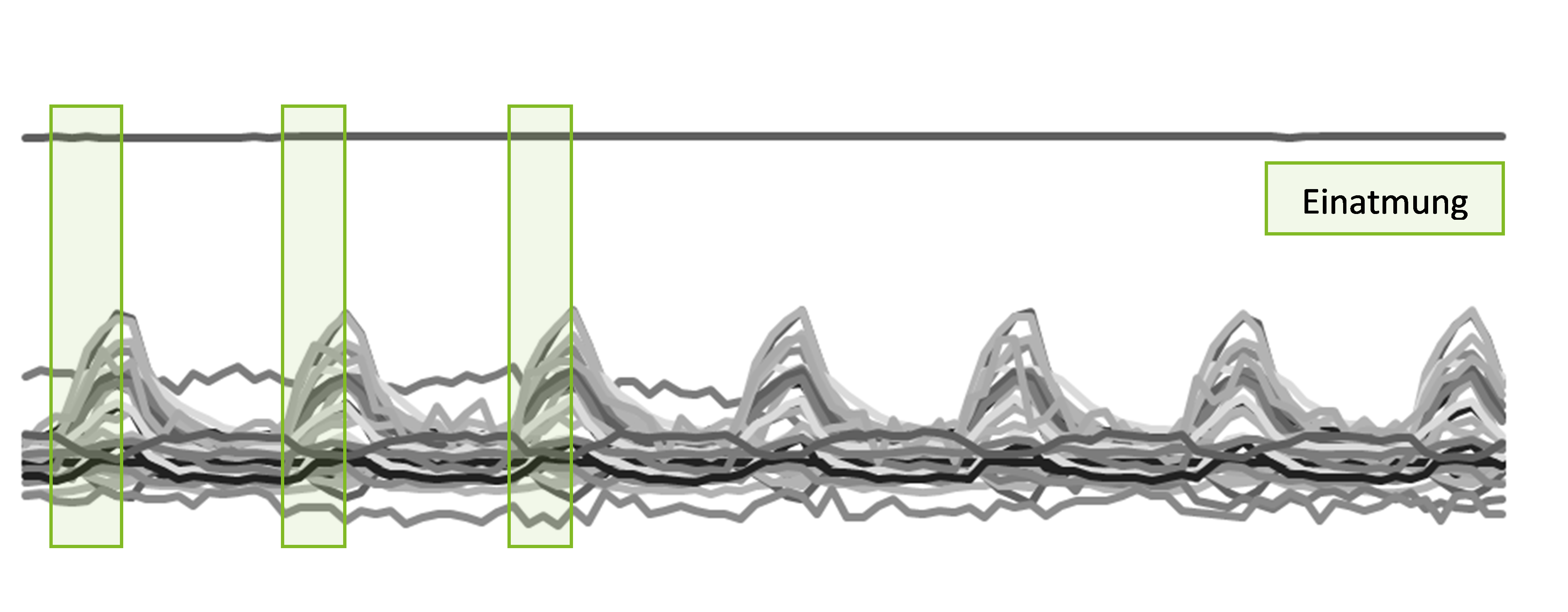
Unsere Ausgangslage und die Idee
In dem Forschungsprojekt erhalten wir Daten von einem sogenannten Sensorpatch. Dabei handelt es sich um eine Art kleines Deckchen, das eine quadratische Anordnung von 36 Sensoren enthält, die ihre eigene Biegung messen. Alle 48 Millisekunden gibt der Sensorpatch Daten aus. Wenn der Computer diese Daten erhält, soll innerhalb kürzester Zeit entschieden werden, ob die Sensoren gerade eine Ein- oder Ausatmungsperiode messen. Durch diese Information soll dann ein Ventil zur Aerosolisierung (Vernebelung) bestimmter Medikamente gesteuert werden.
Der Aufbau des Systems und wie man grundsätzlich von Sensordaten zu gezielten Ergebnissen kommt, ist hier bereits beschrieben: [2]. Vorerst haben wir jedoch noch keinen Sensorpatch zur Hand, sondern nur 3 Dateien mit Beispieldaten.
Unsere Idee ist es, zur Bewältigung dieser Aufgabe verschiedene Algorithmen zu verwenden und diese am Ende zu vergleichen, sodass wir den am besten geeigneten Algorithmus auswählen können. Unter anderem soll ein neuronales Netz zum Einsatz kommen.
Grundlagen
Zunächst jedoch müssen wir uns einige theoretische Grundlagen anschauen.
Neuronale Netze und Deep Learning
Neuronale Netze sind ein Ansatz aus dem breiten Themengebiet des maschinellen Lernens [3]. Maschinelles Lernen ist ein Überbegriff für alle Arten von Algorithmen, die mit einem Trainingsdatensatz aus Beispielen trainiert werden und das Gelernte dann auf neue, potentiell unbekannte Beispiele derselben Art übertragen können. Neben neuronalen Netzen werden beispielsweise auch Entscheidungsbäume und Support Vector Maschinen (SVM) verwendet. Für eine breitere Übersicht über Maschine Learning empfehle ich [4].
Wie in [1] beschrieben, besteht ein neuronales Netzwerk aus sogenannten Neuronen. Hier nur eine kurze Wiederholung: Das Neuron erhält gewichtete Eingabewerte, summiert diese und ermittelt dann anhand seiner Aktivierungsfunktion (hier dargestellt durch einen Schwellenwert) die eigene Ausgabe (siehe Abbildung).
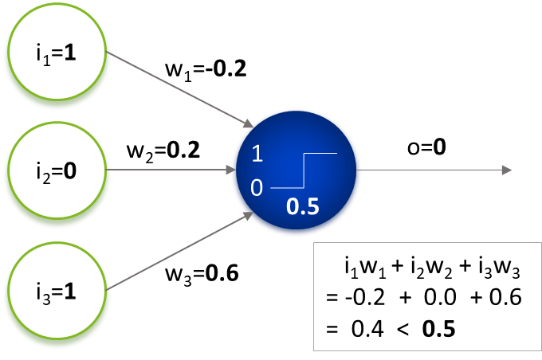
Wenn man mehrere solcher Neuronen miteinander verknüpft, erhält man ein neuronales Netz. Dabei können die Ausgaben eines Neurons als Eingaben für das nächste Neuron verwendet werden. Die Neuronen werden in sogenannten Schichten angeordnet. Jedes Neuron einer Schicht erhält dabei die Ausgaben aller Neuronen der letzten Schicht als Eingaben. Man spricht auch von „Deep Learning“, sobald ein Netz mehrere Schichten hat.
Rekurrente neuronale Netze (RNNs) und Long Short Term Memory Netze (LSTMs)
Bei den Daten, die wir untersuchen, handelt es sich um sogenannte „Zeitreihen“. Ein einzelner Messpunkt kann während der Ein- und der Ausatmung genau gleich aussehen; es ist anhand dieses Messpunktes nicht feststellbar, um welche Atmungsphase es sich handelt. Das neuronale Netz soll deshalb nicht nur den aktuellen Wert, sondern auch die vorigen Werte untersuchen. Bei „normalen“ neuronalen Netzen ist das nicht vorgesehen. Sie heißen auch „Feed Forward“-Netze, weil die Informationen im Netz immer nur in eine Richtung weitergegeben und nicht zwischengespeichert werden können. Netzwerke, die das Wiederverwenden von Informationen durch sogenannte Schleifen erlauben, nennt man Rekurrente Neuronale Netze (RNN). Dabei kann die Ausgabe einer Schicht als Eingabe für dieselbe oder eine frühere Schicht wiederverwendet werden.

Wir nutzen eine besonders häufig verwendete Art von rekurrenten Netzen: Das Long Short Term Memory (LSTM)-Netzwerk. Bei diesen ist jedes Neuron mit einem internen Speicher für frühere Werte ausgestattet. Das Netzwerk lernt dann auch, wann welche dieser Werte nützlich sind und mit einbezogen werden sollten. Eine gute Einführung in LSTM-Netze ist hier zu finden: [5].
Faltungsnetze oder Convolutional Neural Networks (CNNs)
Die Daten, die wir untersuchen, stehen nicht nur in zeitlicher Abhängigkeit, sondern zusätzlich auch in räumlicher, d.h. es spielt eine Rolle, dass die Sensoren in einer bestimmten Art und Weise angeordnet sind. Auch das ist in „normalen“ neuronalen Netzen nicht untersuchbar; die Inputs werden unabhängig voneinander betrachtet. Mit Faltungsnetzen (englisch: Convolutional Neural Networks, kurz CNN), die unter anderem in der Bilderkennung mit beeindruckenden Ergebnissen eingesetzt werden, können diese Abhängigkeiten betrachtet werden. Das CNN verfügt dann über Schichten, die aus sogenannten Kernels bestehen. Das sind Matrizen mit Zahlen, mit denen das neuronale Netz anhand von Faltungsoperationen bestimmte Strukturen (beispielsweise Kanten) „erkennt“. Wie das funktioniert führt leider zu weit für diesen Beitrag, ist aber hier [6] wirklich gut beschrieben. Ein zusätzlicher Vorteil der Faltungsschichten ist, dass sie die gleiche Größe von Eingabedaten mit weniger trainierbaren Parametern erfassen können.
Training
Das neuronale Netz, das wir einsetzen, funktioniert nach dem Prinzip des überwachten Lernens. Das bedeutet, dass es zum Training Daten mit sogenannten Labels gibt, d.h. zu jedem Trainingsdatenpunkt ist bekannt, ob es sich um eine Ein- oder Ausatmung handelt. Während des Trainings kann das neuronale Netz seine berechneten Ergebnisse immer wieder mit den Labels vergleichen und sich in mehreren Iterationen immer mehr daran anpassen. Dabei werden die Gewichte an den Verknüpfungen zwischen den Neuronen verändert. Der Algorithmus, der dazu verwendet wird, nennt sich Backpropagation. Die Funktionsweise ist in [1] bereits umrissen und hier [7] ausführlicher erklärt. Weil während des Trainings alle Gewichte an allen Verknüpfungen angepasst werden müssen, ist dieser Prozess zeitaufwendig und benötigt eine Menge Daten.
Für unser neuronales Netz wird, weil es sich um ein rekurrentes Netz handelt, tatsächlich eine abgewandelte Form des Backpropagation-Algorithmus‘ verwendet, die auch in der Lage ist, bereits vergangene Berechnungen nachträglich zu beurteilen (Backpropagation Through Time) [8].
Daten, Daten, Daten
Daten sind ein essentieller Bestandteil des Trainingsprozesses. Wenn ich an maschinelles Lernen denke, dann habe ich meinen Professor im Kopf, der uns ernst ansieht und zur Einführung in seine Vorlesung sehr deutlich und bestimmt sagt: „Daten, Daten, Daten!“. Es klang, als wolle er etwas beschwören und das hat sich offenbar gut in mein Gedächtnis eingeprägt. In der Tat hängt der Lernerfolg der meisten Machine Learning Ansätze stark von den Trainingsdaten ab – und zwar sowohl von der Menge der Daten als auch davon, wie gut sie die zu lösende Aufgabe repräsentieren.
Wenn wir mit zu wenigen Atmungskurven trainieren, dann kann es vorkommen, dass das neuronale Netz versehentlich lernt, das Rauschen in den Daten als wertvolle Information aufzufassen. Das Problem tritt bei neuronalen Netzen häufig auf und hat daher einen eigenen Namen: Overfitting [9]. Wenn wir dagegen sehr viele Daten haben, aber nur Atmungskurven von einer bestimmten Patientin oder aus einer Simulation betrachten, kann es ebenfalls passieren, dass der Algorithmus sich zu stark an die Daten anpasst. Das hat zur Folge, dass die Ergebnisse zwar für diese Patientin sehr gut sind, sich auf die Daten anderer Patienten schlecht übertragen lassen. Deren Atmungszyklen könnten beispielsweise kürzer oder länger sein oder der Brustkorb bewegt sich unterschiedlich. Auch das wird als Overfitting bezeichnet.
Um diese Probleme anzugehen, können wir eine Methode anwenden, die sich Data Augmentation nennt. Dabei verwendet man die zur Verfügung stehenden Daten beim Training mehrfach, und zwar in leicht veränderter Form. Bilder kann man beispielsweise künstlich spiegeln, leicht verdunkeln oder einen kleineren Bildausschnitt wählen. Das ist zwar nicht ganz so gut wie mehr echte Daten zu haben, aber viel besser als gar nichts. Die Augmentations, die wir verwenden, werden im zweiten Teil dieser Reihe beschrieben.
Ein paar Worte zur Einsetzbarkeit
Künstliche Intelligenzen, insbesondere neuronale Netze jeglicher Form, sind meist sehr komplex. Das ist notwendig, um die (aus der Sicht eines Computers ebenfalls sehr komplexen) Probleme zu lösen, für die sie geschaffen wurden, verhindert aber, dass der Mensch ihre Auswertung und ihr Verhalten vollständig nachvollziehen oder ihre Zuverlässigkeit formal beweisen kann. Besonders im medizinischen Kontext, aber auch überall sonst, wo künstliche Intelligenzen nachvollziehbare Entscheidungen treffen sollen (z.B. um Diskriminierungsfreiheit zu gewährleisten) oder wenigstens garantiert robuste Ergebnisse liefern müssen (z.B. um im Straßenverkehr keine Fehler zu machen) stellt das ein Problem dar. Ein ganzer Forschungszweig beschäftigt sich mit sogenannter SafeAI (also „sicherer künstlicher Intelligenz“) und es gibt bereits einige Ansätze, um die Systeme erklärbarer, transparenter oder robuster zu machen, hier steht die Forschung aber noch ziemlich am Anfang. [3]
Solange die Nachvollziehbarkeit nicht gegeben ist, ist es umso wichtiger, die Systeme sehr gründlich zu testen. Außerdem sollten für den Notfall Sicherheitsmechanismen eingebaut werden. In unserem Projekt bauen wir beispielsweise einen Timer ein – wenn für eine bestimmte Zeit kein Wechsel der Atemphasen erkannt wurde, ist es wahrscheinlich, dass etwas mit dem neuronalen Netz nicht stimmt. In dem Fall schaltet es sich ab und „übergibt“ die Überwachung an einen klassischen Algorithmus. Ein solches Verfahren nennt sich Monitoring und ist eine der Maßnahmen, die zum Beispiel vom Fraunhofer IKS empfohlen werden, wenn es darum geht, neuronale Netze zuverlässiger und sicherer zu gestalten [10].
Letztendlich kann es trotzdem sinnvoller sein, von vorn herein einen klassischen Algorithmus zu wählen – selbst wenn dieser für die Testdaten etwas schlechtere Ergebnisse liefert – weil seine Entscheidungen vorhersehbar sind. Diese Entscheidung kann zum aktuellen Zeitpunkt noch nicht getroffen werden.
Zusammenfassung und Ausblick
Bisher haben wir ein einführendes Beispiel gegeben, um ein intuitives Verständnis für die Funktionsweise von neuronalen Netzen zu vermitteln und einige Grundlagen erläutert. Neuronale Netze sind ein Ansatz aus dem Bereich des maschinellen Lernens. Sie funktionieren, indem sie sich in einem iterativen Lernprozess auf Beispieldaten anpassen und die Erkenntnisse dann auf neue Beispiele übertragen. Wir setzen Variationen von neuronalen Netzen ein, mit denen auch die zeitlichen und räumlichen Abhängigkeiten unserer Sensordaten gelernt werden können.
Wir haben auch erklärt, dass ein neuronales Netz, selbst wenn es im Test die besten Ergebnisse liefert, nicht zwingend das Mittel der Wahl ist. Das liegt daran, dass durch seine Komplexität für den Menschen nicht jeder Schritt nachvollziehbar ist und man seine Zuverlässigkeit deshalb nicht formal beweisen kann.
Zurück zu unserem Anwendungsfall. Wir haben bisher nur die Daten. Ein neuronales Netz müssen wir erst noch „bauen“ und natürlich wollen wir es nur dann einsetzen, wenn es „gut“ funktioniert. Aber wie bauen wir das neuronale Netz auf? Und woher wissen wir, wie gut es funktioniert? Die Antworten zu diesen Fragen beleuchten wir im zweiten Teil unseres Blogbeitrags!
Quellen
- https://eckcellent-it.blog/neuronale-netzwerke-was-steckt-dahinter/
- https://eckcellent-it.blog/von-sensordaten-zu-gezielten-erkenntnissen/
- https://www.bigdata.fraunhofer.de/content/dam/bigdata/de/documents/Publikationen/Fraunhofer_Studie_ML_201809.pdf
- https://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
- Teil: https://www.youtube.com/watch?v=YIqYBxpv53A, 2. Teil: https://www.youtube.com/watch?v=EAtQCut6Qno
- https://machinelearningmastery.com/gentle-introduction-backpropagation-time/
- https://elitedatascience.com/overfitting-in-machine-learning
- https://www.iks.fraunhofer.de/de/themen/kuenstliche-intelligenz/absicherung-ki.html
- Titelbild: Owen Beard auf Unsplash – https://unsplash.com/photos/K21Dn4OVxNw

Softwareentwicklung